本文分为相关概念、基本结构、压缩方式等方面展开。
一、H.264相关概念
1、帧
在H.264中,一帧表示一个视频图片编码后的数据,一帧由一个或多个片组成,一个片由一个或多个宏块组成,一个宏块由16x16的yuv数据组成。
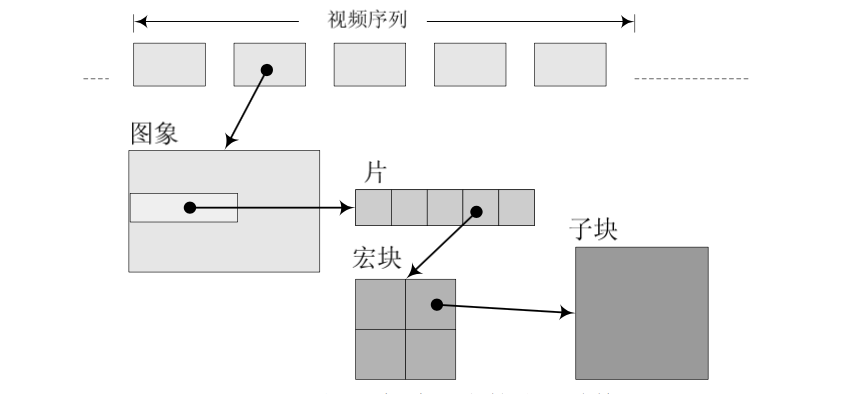
2、I、B、P帧
H.264标准中,定义了I帧、B帧、P帧。
I帧:帧内编码帧(intra picture)。是完整的一个图像,单独拿出来可以查看。I帧是每个GOP的第一个帧,经过简单地压缩,作为随机访问的参考点。 在Android中,MediaMetadataRetriever.java#getFrameAtTime(0),会返回一张图片,作为视频的封面、缩略图,在底层的实现中,就是遍历0S之后的数据, 拿到第一个I帧,然后返回这张图片。注:getFrameAtTime(-1),并不是随机返回一个I帧,而是在视频中寻找,找出最大的(持续时间最长的)有效帧,然后返回它的I帧。
P帧:前向预测编码帧(predictive-frame),表示的是这一帧跟之前的I帧(或者P帧)的差别。解码时需要用之前的I帧,叠加上本帧,生成最终的画面。 所以P帧是差别帧,P帧没有完成的画面数据,单独抽出来是无法查看的。
B帧:双向预测内差编码帧(双向差别帧、双向预测帧)(bi-directional interpolated prediction frame)。也是差异帧,既考虑源视频序列前面的已编码帧, 也考虑视频序列后面已编码帧,来压缩产生B帧。 要解码B帧,不仅要获取之前的缓存画面,也要解码之后的画面,然后叠加本帧数据得到最终的画面。B帧的压缩率高,但是解码会大量消耗CPU资源。
注: I帧是完整的视频帧,换句话说,客户端只有在获得I帧后才会有完整的视频。如果直接发送,不等I帧,客户端得到的画面会残缺,但是延迟较低。如果等I帧,客户端缓冲时间较长,得到画面会完整,但是延迟至少是一个GOP。视频通话、播放网络视频时,如果出现花屏现象,一般是由于I帧丢失导致的,可以通过等待I帧后展示画面解决。
3、GOP
Grop Of Picture,两个I帧之间的视频帧,包括1个I帧+多个P帧+多个B帧。GOP:IBBPBBPBBPBBI。 一般是一段时间内变化不大的视频帧集。在一个GOP内I frame解码不依赖任何的其它帧,p frame解码则依赖前面的I frame或P frame,B frame解码依赖前最近的一个I frame或P frame 及其后最近的一个P frame。
4、IDR帧
在编解码中,把第一个I帧叫做IDR帧,方便控制编码和解码流程,所以IDR帧一定是I帧,反之不成立。IDR帧的作用是立即刷新,避免误码的传播,从IDR帧开始,后面的B、P帧不能参考IDR之前的I帧。
I帧不用参考任何帧,但是之后的P、B帧协议参考这个I帧和之前的I帧。
IDR1 P4 B2 B3 P7 B5 B6 I10 B8 B9 P13 B11 B12 P16 B14 B15 这里的B8可以跨过I10去参考P7
IDR1 P4 B2 B3 P7 B5 B6 IDR8 P11 B9 B10 P14 B11 B12 B13 B14 这里的B9就只能参照IDR8和P11,不可以参考IDR8前面的帧
IDR帧,是为了解码的同步,当解码器解码到IDR图像时,立即将参考队列清空,将已解码的数据全部输出或者抛弃,重新查找参数集,开始一个新的序列。 这样, 如果前面的序列出现重大错误,在这里也可以获得重新同步的机会。
二、H.264的基本结构
H.264从功能划分为两个层次:视频编码层(Video Coding Layer)和网络抽象层(Network Abstraction Layer)。
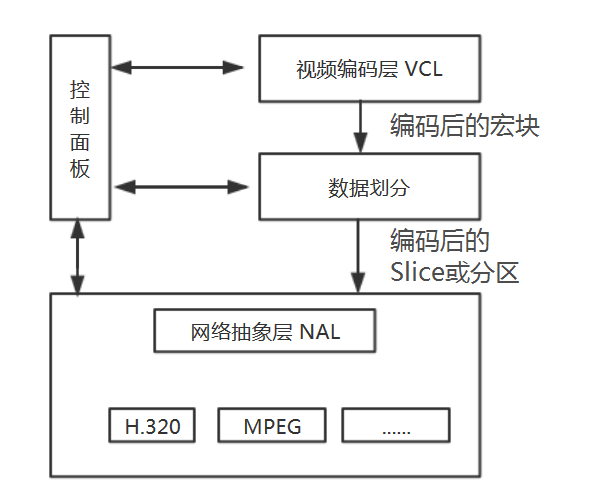
VCL负责有效地表示视频数据的内容,最终输出编码完的SODB。
NAL负责格式化数据并提供头信息,以让数据在各种信道和存储介质上的传输。NAL层将SODB打包成RBSP然后加上NAL头组成一个NALU单元 我们平时的每帧数据就是一个NAL单元。

三、H.264的压缩方式
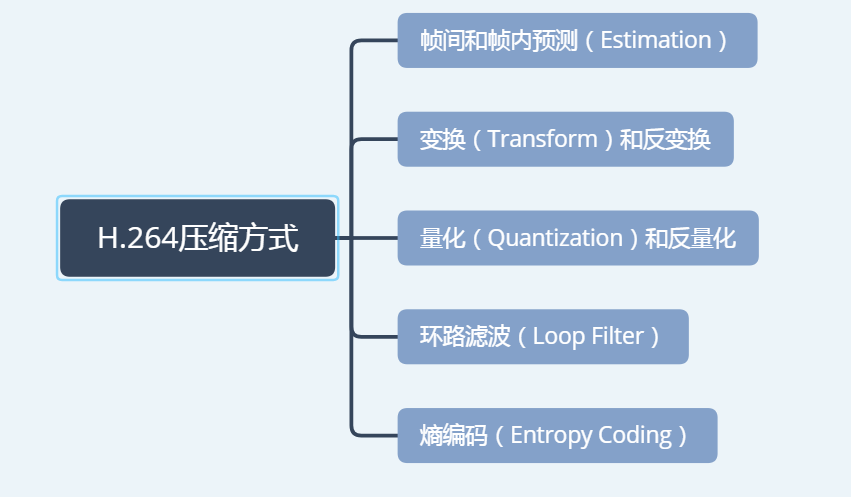
首先,H.264划分宏块的方式:
以下面这张图片为例:

H.264默认使用16x16像素大小的区域作为一个宏块,也可以细分为8x8像素大小。

划分好宏块后,计算宏块的象素值。

以此类推,计算一幅图像中每个宏块的像素值,所有宏块都处理完后如下面的样子。

H264对比较平坦的图像使用 16X16 大小的宏块。但为了更高的压缩率,还可以在 16X16 的宏块上更划分出更小的子块。子块的大小可以是 8X16、 16X8、 8X8、 4X8、 8X4、 4X4非常的灵活。

上幅图中,红框内的 16X16 宏块中大部分是蓝色背景,而三只鹰的部分图像被划在了该宏块内,为了更好的处理三只鹰的部分图像,H264就在 16X16 的宏块内又划分出了多个子块。

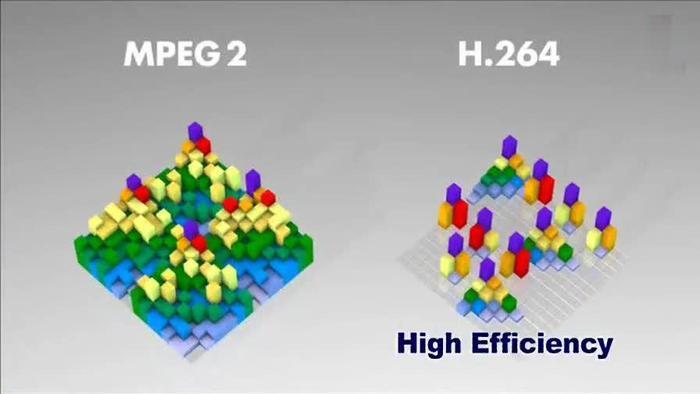
这样再经过帧内压缩,可以得到更高效的数据。下图是分别使用mpeg-2和H264对上面宏块进行压缩后的结果。其中左半部分为MPEG-2子块划分后压缩的结果,右半部分为H264的子块划压缩后的结果,可以看出H264的划分方法更具优势。
帧内预测
对特定的宏块编码时,利用周围的宏块的预测值和实际值的差进行编码。
人眼对图像有一个识别度,对于低频的亮度很敏感,对于高频的亮度不太敏感,
所以基于一些研究,可以将一副图像中,人眼不敏感的数据去除,这样就提出了帧内预测技术。
H.264的帧内压缩和JPEG很相似。一副图像被划分好宏块后,对每个宏块可以进行9种模式的预测,找出与原图最接近的一种预测模式。

下面这幅图是对整幅图中的每个宏块进行预测的过程,每个宏块都会记录下最适用的预测模式:

帧内预测后的图像和原始图像对比如下:

然后,将原始图像与预测图像相减得到差值:

最后,将我们的预测模式、差值一起保存起来,这样就能在解码时得到恢复原图了。
帧内压缩类似于图片压缩,跟前一帧和后一帧无关,而是由当前帧中,已编码的部分来推测当前待编码的这一部分数据是什么。

假设现在是按顺序来编码,第一行已经编码完成,⑤也编码完成,正好要压缩⑥这一宏块。 可以看出,它周围的①②③④⑤,跟⑥是一样的(或者差别很小)。如果能用①②③④⑤来预测⑥的图像,显然比直接压缩⑥要更节省空间。这就是帧内预测。
一般来说,视频的第一帧是帧内预测帧(因为它没有其他帧可以参考)。场景切换时是帧内预测帧。
帧间预测
利用连续帧的时间冗余来进行运动估计和补偿。码流中增加SP帧,方便在不同码率和码流间切换,同事支持随机接入和快速回放。
帧分组
对于视频数据,主要有两类数据荣誉,一类是时间上的数据冗余,一类是空间上的数据冗余。其中时间上的数据冗余是最大的。
时间上的空间冗余为何最大? 假设摄像头美妙抓取30帧,这30帧的数据大部分情况下是相关联的,画面变化不大。对于这些关联特别密切的帧,我们可以只保存一帧的数据,其他帧可以通过这一帧,按照某种规则预测出来。
为了达到相关联的帧,通过预测的方法来压缩数据,就需要将视频帧进行分组。
如何判定某些帧关系密切,可以划分为一组呢?看一个例子,一组运动的台球的视频帧,台球从右下角滚到了左上角。


编码器会按照顺序,每次取出两幅相邻的帧做宏块比较,计算两帧的相似度:

通过宏块扫描与宏块搜索,可以发现这两帧的关联度是非常高的。 进而发现这一组帧的关联度都是很高的。 因此上面这几帧可以划分为一组。具体标准是:在相邻几幅图像画面中,一般有差别的像素只有10%以内的点,亮度差值变化不超过2%,色调差值变化在1%之内,可以划分为一个帧分组。
在这样一组帧中,经过编码后,我们只保留第一帧的完成数据,其他帧都通过参考上一帧计算出来。 这也就是我们之前说的,第一帧是I帧,其他帧是P/B帧,这样编码后的数据帧组,称为GOP。
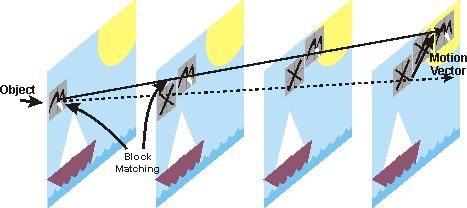
运动估计与补偿 在H.264编码器中,帧分组完成后,就要计算帧分组内物体的运动矢量了。 以台球视频为例,我们看一下它是如何计算运动矢量的。
H.264编码器首先会按顺序从缓冲区头部取出两帧视频数据,然后进行宏块扫描。 当发现其中一幅图片中有物体时,就在另一幅图的临近位置(搜索窗口中)进行搜索。如果此时另一幅图中找到该物体时,就可以计算出物体的运动矢量了。

通过上图中台球位置相差,就可以计算出台图运行的方向和距离。H264依次把每一帧中球移动的距离和方向都记录下来就成了下面的样子:

运动矢量计算出来后,将相同部分(也就是绿色部分)减去,就得到了补偿数据。我们最终只需要将补偿数据进行压缩保存,以后在解码时就可以恢复原图了。压缩补偿后的数据只需要记录很少的一点数据。如下所示:

我们把运动矢量与补偿称为帧间压缩技术,它解决的是视频帧在时间上的数据冗余。除了帧间压缩,帧内也要进行数据压缩,帧内数据压缩解决的是空间上的数据冗余。
如果摄像头没有晃来晃去,那么,在连续的视频图像里面,前后两帧的差别真的很小,比一张图片中连续两个宏块的差别还要小,这时用帧间压缩的效果会比帧内压缩的效果好。
Block Matching 就是块匹配,就是查找前面已经编码的帧中,和我当前这个快最类似的一个快,这样就不用编码当前宏块的内容了,只需要编码当前宏块和我找到的那个宏块的差(残差)。找最像的宏块的过程叫做运动搜索(运动估计)。用残差和原来的宏块计算出真实的当前宏块,这个过程叫做运动补偿。